
Researcher Metehan Ozten downloaded, extracted, and mapped the complete tokenizer powering OpenAI’s current models. His analysis of the raw encoding files reveals concrete shifts in how these models process text, code, entities, and multilingual content. For anyone optimizing content to appear in AI-generated answers, these changes carry practical weight.

GPT-5 Tokenizer Reverse-Engineered: Guide for SEO & AEO
What Metehan Found
OpenAI’s newer models use a tokenizer called o200k_base. It powers GPT-4o, o1, o3, o4-mini, and GPT-5, replacing the cl100k_base tokenizer used by earlier GPT-4 variants. The vocabulary nearly doubled: from 100,277 tokens to 200,019.
Metehan obtained the full token set by downloading the publicly accessible .tiktoken and .jsonl files from OpenAI’s Azure storage via the tiktoken repository. He then cataloged all 200,019 entries and ran comparative tests against cl100k_base to measure efficiency gains across languages, code, and named entities.
He also identified a variant called o200k_harmony, which reserves approximately 1,075 special token slots beyond the base vocabulary. These reserved slots are linked to GPT-5’s agentic capabilities, giving the model a richer internal vocabulary for function calls and tool interactions.
Five changes stand out for the AEO/GEO community:
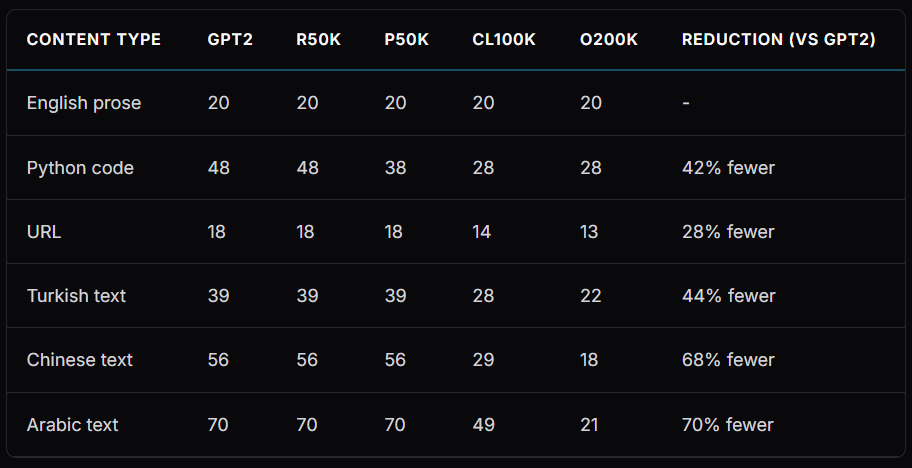
1. Fewer tokens per input, more room in the context window. A sentence that cl100k split into 15 tokens might become 10 or 11 under o200k_base. The same 128K token limit now fits more actual text, more retrieved documents, more of your content.
2. Multilingual tokenization improved dramatically. Arabic saw a 70% reduction in token count (a 3.3x efficiency gain). Chinese saw a 68% reduction. Languages like Turkish, Vietnamese, and Japanese that previously required many tokens for common words now encode far more efficiently.
3. The regex layer was completely rewritten. The new tokenizer is camelCase-aware at the splitting stage. It breaks camelCase into camel + Case before the input ever reaches the BPE algorithm. This is a structural change in how the model “sees” compound words and code identifiers, not just the addition of new token entries.
4. Brand and entity names became atomic. Names like Google, Amazon, and Bentley are now single tokens. Under cl100k, many of these were split across two or three tokens. Metehan argues this is significant: single-token entities are less likely to be hallucinated than multi-token entities, because the model treats them as indivisible units rather than sequences it must reconstruct.
5. Code and structured data got dedicated tokens. Common programming patterns, JSON keys, HTML tags, and whitespace sequences have their own entries. Structured content costs less of the token budget to process.
Why This Matters for AEO and GEO
If you optimize content for visibility in AI-generated answers, tokenizer changes affect you at the retrieval, processing, and generation layers.
Your content competes inside a fixed token budget. When GPT-5 retrieves web pages to answer a query, it stuffs them into its context window alongside the user’s prompt, system instructions, and its own reasoning. Under o200k_base, each page costs fewer tokens to include. The model can retrieve and consider more sources per query. Pages that previously got cut for space might now make it into the context. The competitive field expands.
Structured content gets cheaper to process. Clean HTML, schema markup, and data tables burn fewer tokens than the same information in dense paragraphs. In retrieval-augmented generation (RAG) pipelines, where the model must decide which retrieved chunks to keep and which to discard, token-efficient content has an edge.
Brand atomicity changes the hallucination calculus. If your brand name is a single token, GPT-5 treats it as one unit. It cannot partially reconstruct it or swap in a similar-sounding competitor mid-generation. Brands that made it into the o200k_base vocabulary as atomic tokens have a structural advantage in citation accuracy. Brands that didn’t may still be split across tokens and remain more vulnerable to misattribution.
Non-English content gains ground. AEO strategy has been English-dominant partly because English tokenized most efficiently. That gap narrowed. With Arabic at 3.3x more efficient and Chinese at 68% fewer tokens, non-English pages fit more comfortably within context limits. Expect AI models to handle and cite non-English sources more readily.
A deliberate investment in making models genuinely multilingual – Credit: Metehan.ai
The Sonic Classifier and Fan-Out Engine add another layer. Metehan cross-references his tokenizer findings with RESONEO’s research into GPT’s internal retrieval architecture. The “Sonic Classifier” decides whether a query needs web search based on how the tokenized input maps to the model’s existing knowledge. The “Fan-Out Engine” then breaks a single query into multiple parallel searches. Both systems operate on tokenized input. Changes in how text tokenizes change which queries trigger retrieval and how broadly the model searches. Your content’s discoverability is shaped by tokenization before any ranking signal comes into play.
What Practitioners Should Do
Check your brand’s token status. Test whether your brand name tokenizes as a single unit under o200k_base (you can do this with OpenAI’s tiktoken library or online tokenizer tools). If it does, your brand has structural protection against hallucination in GPT-5 outputs. If it splits across multiple tokens, that’s a vulnerability worth understanding.
Audit your structured data. Pages with clean HTML hierarchy, schema markup, and structured tables are now even more token-efficient relative to unstructured prose. The tokenizer math tilts further toward structured formats.
Watch your multilingual properties. If you run sites in Arabic, Chinese, Turkish, Vietnamese, or Japanese, test how GPT-5 handles queries in those languages. Your non-English pages are less likely to get truncated or dropped from the context window during retrieval.
Revisit content density. Fewer tokens per word means the model processes more of your page before hitting limits. Long-form content that previously got cut off mid-page may now be read in full. Front-loading your core argument still matters, but the penalty for depth got smaller.
Track citation patterns across model versions. Metehan’s research confirms that GPT-5 uses a fundamentally different text processing layer than GPT-4.
The Bigger Picture
Tokenizer changes are infrastructure. They sit below the layer most SEO practitioners think about. But in a world where AI models retrieve, process, and cite web content inside fixed computational budgets, the tokenizer determines how much of the web the model can see per query.
This study gave the optimization community a structural map of GPT-5’s text processing layer. The practitioners who adjust their content architecture accordingly will have an edge in AI-generated citations.

Leela Adwani
AI Visibility Researcher and Editor